您正在閱讀隱私權教戰手冊的第 2 章 (共 3 章)。跳到其他章節:3. 持續放送切合需求的廣告以提高成效或 1. 與消費者建立直接往來關係。



做法
線上服飾零售商 MandM Direct 希望能透過保護隱私權的方式來維持廣告活動評估成效。該公司首先在整個網站上導入全網站標記,並採用 Google 的全新數據分析平台 Google Analytics (分析) 4。接著,該公司採用
強化轉換,並使用同意聲明模式,進一步提升這些工具的準確度和完整性,因此就算使用者不同意使用 Cookie,網站代碼仍可仰賴轉換模擬功能。
成果
導入強化轉換後,MandM 在搜尋聯播網和 YouTube 上記錄到的轉換量分別增加 3% 及 20%,而採用同意聲明模式則另外讓轉換量提升了 15%。
運用機器學習技術,填補消費者流程中的評估缺口並取得深入分析資料
使用者會切換使用裝置或從線上轉往離線,再加上瀏覽器限制和各種同意聲明選項的規範,即使有了強大的可觀測成效評估資訊基礎,消費者流程中出現評估缺口也是在所難免。
此時機器學習技術就能發揮功效,填補不完整的評估資料。以轉換模擬為例,這不僅是 Google 成效評估解決方案長久以來的重要功能,未來也會是我們不可或缺的功能。模擬功能會使用可觀測的信號,以保障隱私權的方式全方位描繪整體成效。由於各廣告消費者的消費者組合可能有截然不同的行為,因此不會有一體適用的模式。
以下說明這項功能如何因應各廣告消費者的需求
步驟 1:
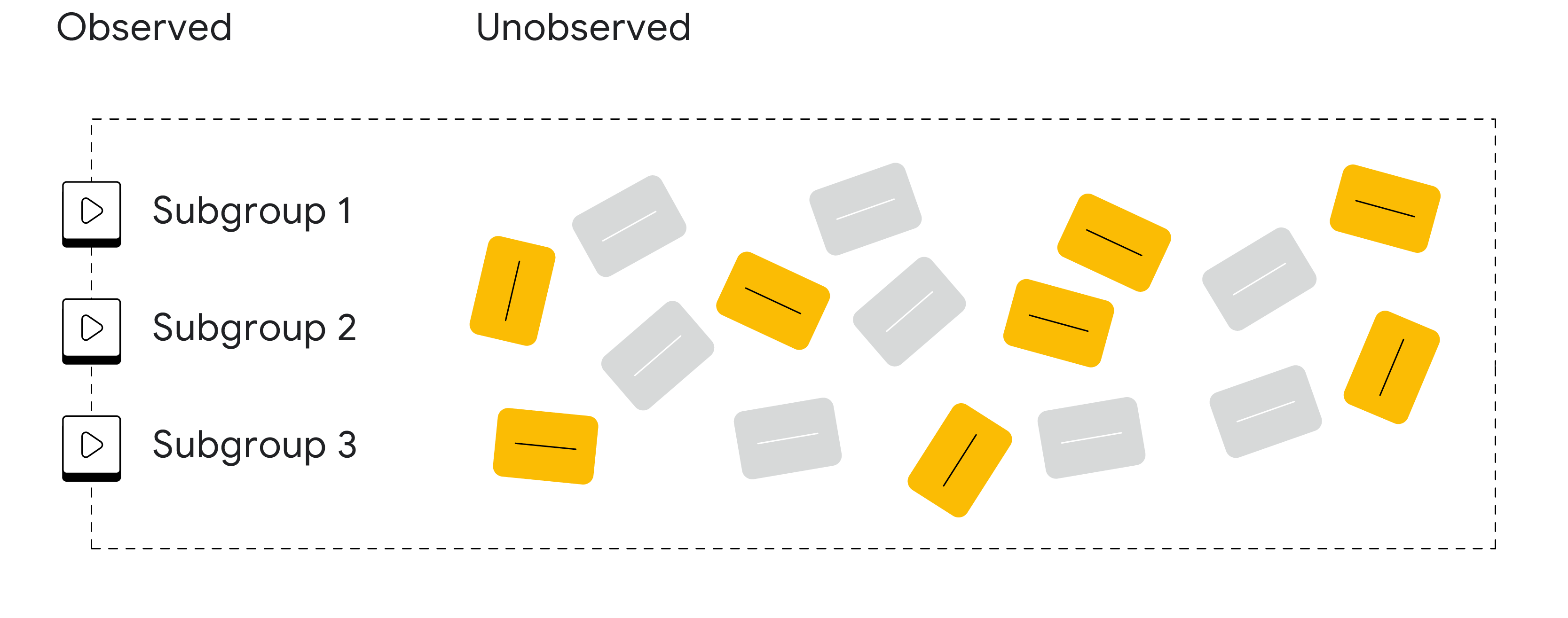
我們將廣告互動分成 2 組:可觀察到廣告互動與轉換之間關聯的為一組,無法觀察到的則分在另外一組。
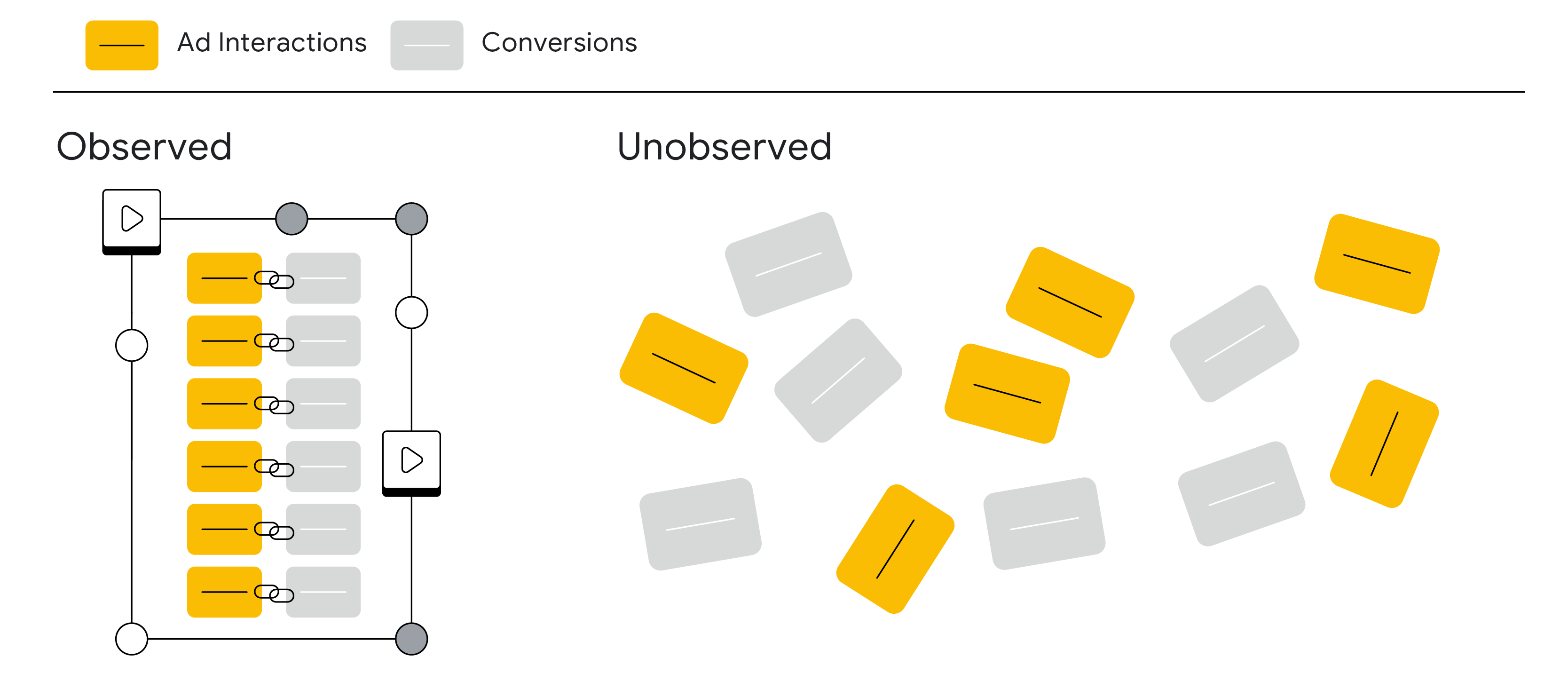
步驟 2:
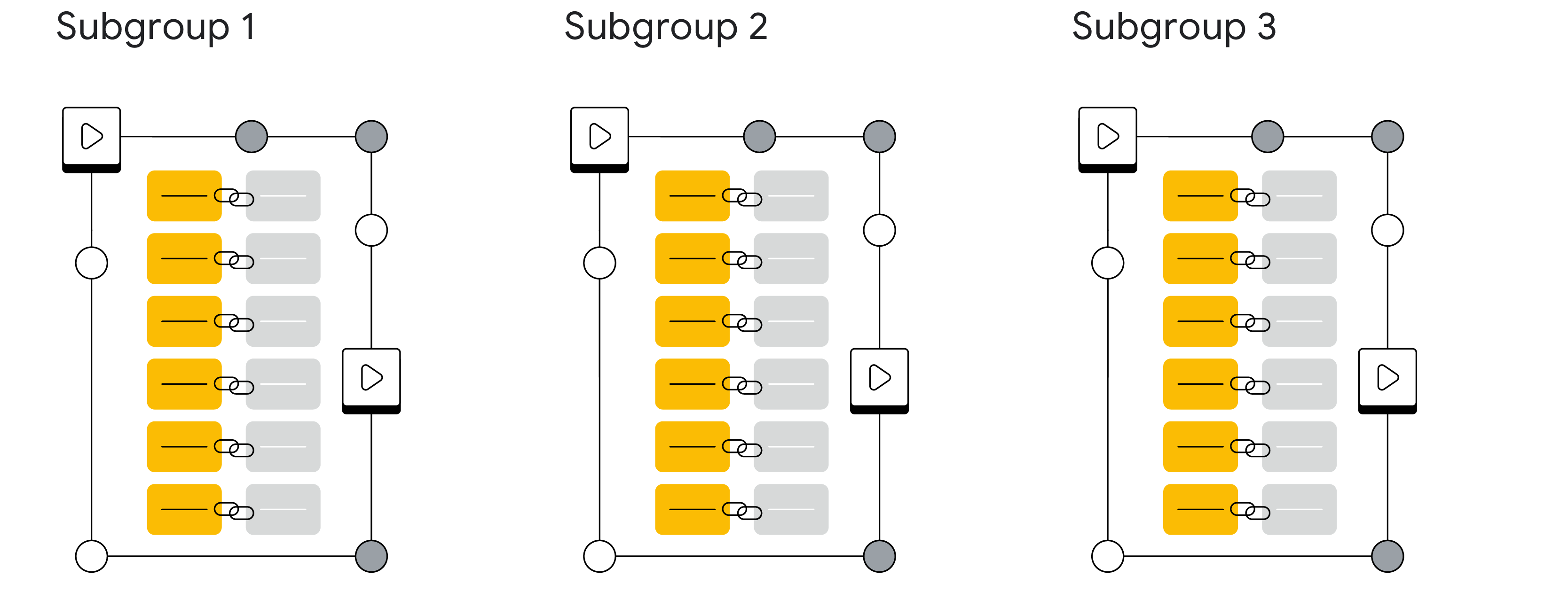
我們會根據共同的非敏感特徵將可觀察的群組細分為不同的子群組,例如:裝置類型、瀏覽器、國家/地區、轉換類型等。
步驟 3:
我們會計算每個子群組的轉換率。
步驟 4:
接著,我們會根據共同特徵,將缺少關聯資訊的廣告互動和轉換指派給其中一個現有的子群組。
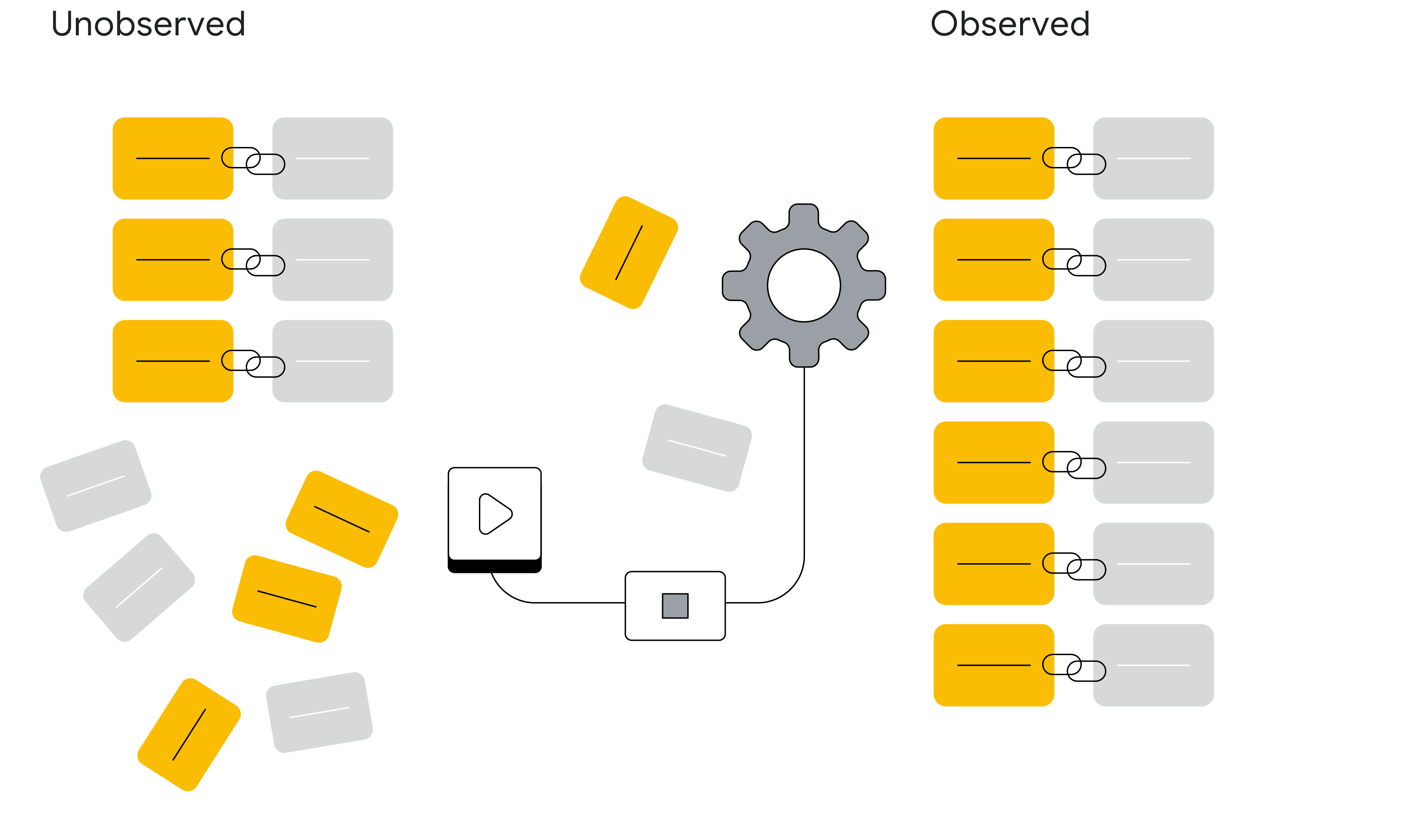
例如:子群組 1 可能全都位於法國、使用 Chrome 瀏覽器且裝置為 iPhone。我們在「未觀察到關聯」的群組中發現廣告互動和轉換資料具有類似的特
徵,但這些維度中有一項不相符 (例如:瀏覽器類型),而且正是我們嘗試預測的特徵。因此,我們會根據這些群組的相似之處妥善進行分類。
步驟 5:
我們會利用機器學習技術,以及從觀察樣本取得的已知轉換率,模擬未觀察到關聯的廣告互動應屬於哪個缺少關聯的轉換。
注意:我們的數據資料學家會持續改良演算法,以提升準確度和作業規模。此外,我們會使用預留驗證等方法,主動測試及驗證模型以改善準確度,藉此定期評估系統偏誤及不準確之處,並持續改進模擬功能。
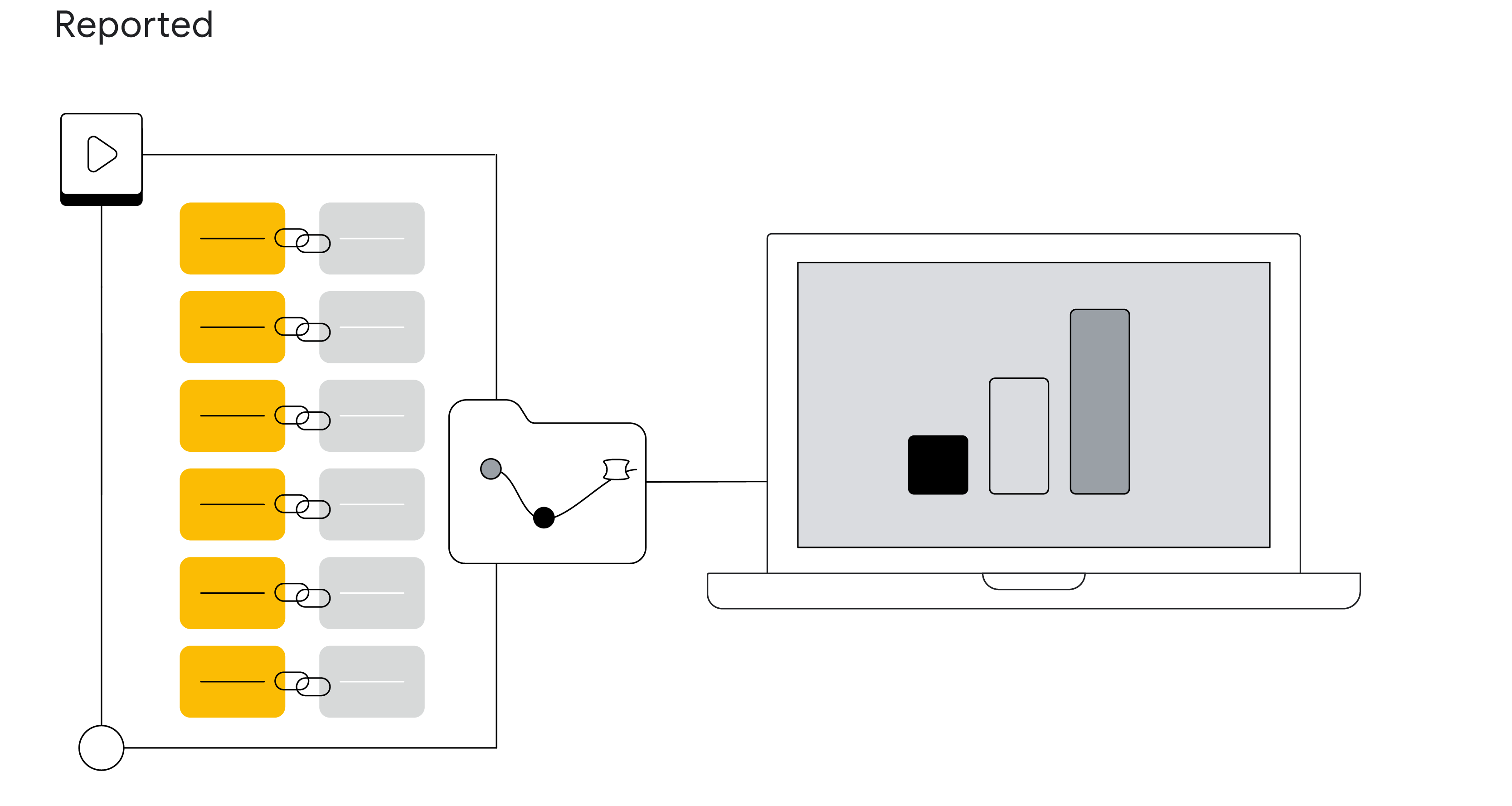
步驟 6:
一旦廣告互動和轉換彼此有合理關聯,我們便會將相關資料彙整在報表中。我們只會在確信轉換歸因於廣告互動時,才會將模擬轉換納入報表。這套嚴謹的做法可避免系統性的浮報情形。
透過第一方資料取得更多深入分析資料
模擬功能可讓 Google Ads 中的智慧出價等產品存取更多完整資訊,進而發揮更大效益,為您的廣告活動奠定成功基礎,同時以保護使用者隱私為第一要務。
除了提供更完整的轉換評估和最佳化調整,模擬功能還能讓您從行為分析資料中獲取新的消費者洞察。舉例來說,Google Analytics (分析) 4 使用進階機器學習模型,可從您的應用程式和網站第一方資料發掘消費者洞察,並運用這些洞察分析來改善行銷做法。
而 Google Ads 的以數據為準歸因功能則會利用進階機器學習技術,進一步透過分析資料來判斷各行銷接觸點對促成轉換的貢獻,同時兼顧使用者隱私。和所有 Google 的成效評估解決方案一樣,對於使用者資料在歸因流程中的運用方式,我們尊重使用者的決定;而針對數位指紋採集等會侵害使用者隱私的隱密追蹤技巧,我們亦設有嚴格的政策規定。
為協助所有廣告消費者善用成效更佳的歸因功能,以因應現今不斷變遷的隱私權環境,現在 Google Ads 中所有的新轉換動作都是採用「以數據為準歸因」做為預設歸因模式。
一窺未來的樣貌
Chrome 的 Privacy Sandbox 目標是開發新技術,讓您不必追蹤個別使用者在網路上的活動,也能取得需要的報表與洞察。
比方說,在記錄使用者動作時限制資料數量並在報表中加入隨機資料
(干擾),讓使用者能保持匿名,而不是以可能透露使用者身分的做法,
來評估他們在網路上的行為。
以下說明運作方式
網路瀏覽器將會比對廣告消費者網站上發生的轉換,以及網路上有人點擊或觀看的廣告,並且會以不透露使用者身分的方式來回報資訊,例如匯總資料和限制各轉換可分享的資訊數量。
Privacy Sandbox 技術可搭配第一方資料和機器學習等其他功能一起使用,以利 Google 的成效評估解決方案發揮效益。