기업과 마케팅 담당자는 '고객이 지금, 무엇을, 어떻게 구매하고 있는가'에 대해서만 생각하며 즉각적인 거래에만 초점을 맞추는 경우가 많습니다. 이러한 마케팅 전략에서는 고객의 가치를 단기적으로만 평가하게 됩니다.
그러나 장기적으로 수익성 있는 성장을 도모하고자 한다면, 고객 생애 가치(Customer Lifetime Value, CLV)를 반드시 고려해야만 합니다. CLV는 기업이 한 고객과의 관계를 유지하는 동안 얻는 총 가치를 측정하는 지표로, 비즈니스 성장을 위해 가장 가치 있는 고객을 획득하고 개발하며 유지하기 위해 활용할 수 있습니다.
기업은 단기적인 거래 규모 확장에 집중하는 대신 장기적인 고객 관계에 투자할 수 있는 방법을 더 명확하게 이해함으로써 혜택을 얻을 수 있습니다.
CLV는 각 고객의 미래 가치를 하나의 지표로 간단하게 정량화해주지만, 이를 구현하기란 쉽지 않습니다.
다음은 기업이 비즈니스에서 CLV를 도입하고자 할 때 도움이 되는 5가지 팁입니다.
1. 가능한 한 먼 미래를 내다보세요
CLV가 유용하다는 것이 알려져 있음에도 불구하고, 예측 지표에 기반한 장기적인 전략으로 전환하게 될 경우 위험을 수반하게 된다고 생각하는 경우가 있습니다. 이러한 우려는 대부분 CLV 모델이 잘못되었거나, 고객이 다른 비즈니스에서와 다르게 행동할 경우 등을 가정한 것입니다. CLV 모델에서 미래의 현금흐름을 예측하기 위한 할인 계수(Discount Factor)를 결정하는 데는 어느 정도의 위험성과 불확실성이 동반됩니다. 이러한 위험성을 완화하기 위해 기업이 기존의 단기적 사고방식을 반영해 향후 6개월 또는 12개월의 예측에 맞추어 CLV를 계산하는 경우가 많습니다.
그러나 이러한 방법을 따르면 오히려 역효과가 일어날 수 있습니다. 미래에 대한 예측 범위를 좁히면 가치 있는 비즈니스 기회를 놓칠 수 있으며, 구매 빈도는 드물어도 한 번 구매할 때 많은 금액을 지출하는 가치 있는 중요한 고객을 놓칠 수 있습니다. CLV를 어떻게 도입해야 할지 결정하기 어렵다면 단기 및 장기적인 관점을 모두 고려하여 CLV 모델을 운영하고, 이 둘 사이에 실제로 발생하는 격차에 초점을 맞추세요. 얼마나 큰 이득을 포기하게 되는지 따져보고, 단기적으로는 어떤 고객 또는 행동을 놓치게 되는지, 또, 더 빠른 이익을 실현해야 하는 비즈니스의 압박을 감수하면서도 장기적 관점에서 고객을 확보할 수 있도록 마케팅 노력을 어떻게 조정할 수 있는지에 대해 생각해봐야 합니다.
2. 지나치게 세세한 데이터에 집중하지 마세요
머신러닝과 방대한 양의 데이터를 활용할 수 있게 되면서 어떤 회사들은 ‘이 고객들은 이 특정 시장에서 구매 의도를 보이고, 이러한 유형의 기기에서 수요일마다 오후 3~4시 사이에 우리 브랜드와 접한다’와 같이 주요 고객에 대해 놀랍도록 상세한 행동 프로필을 구축하게 되었습니다. 이런 내용은 인상적이긴 하지만, 사실상 이와 똑같은 행동을 보이는 고객은 많지 않기 때문에 이 정도의 정밀도는 오히려 비즈니스에 도움이 되지 않습니다. 낚시에 비유하자면, 낚시대보다 그물을 사용하는 편이 생산량을 높일 수 있는 것과 같습니다. 사용자 행동을 분류하고자 할 때는 잠재고객의 규모를 염두에 두세요. 현재 확보한 고객보다 더 가치 있는 고객을 찾고자 한다면 더 폭넓은 대상을 들여다보는 것부터 시작하여 세부적으로 파고드들어야 합니다. 그러나 너무 상세한 데이터에 집중하지 않도록 주의하세요.
3. 적시적소에 필요한 접근 방식을 사용하세요
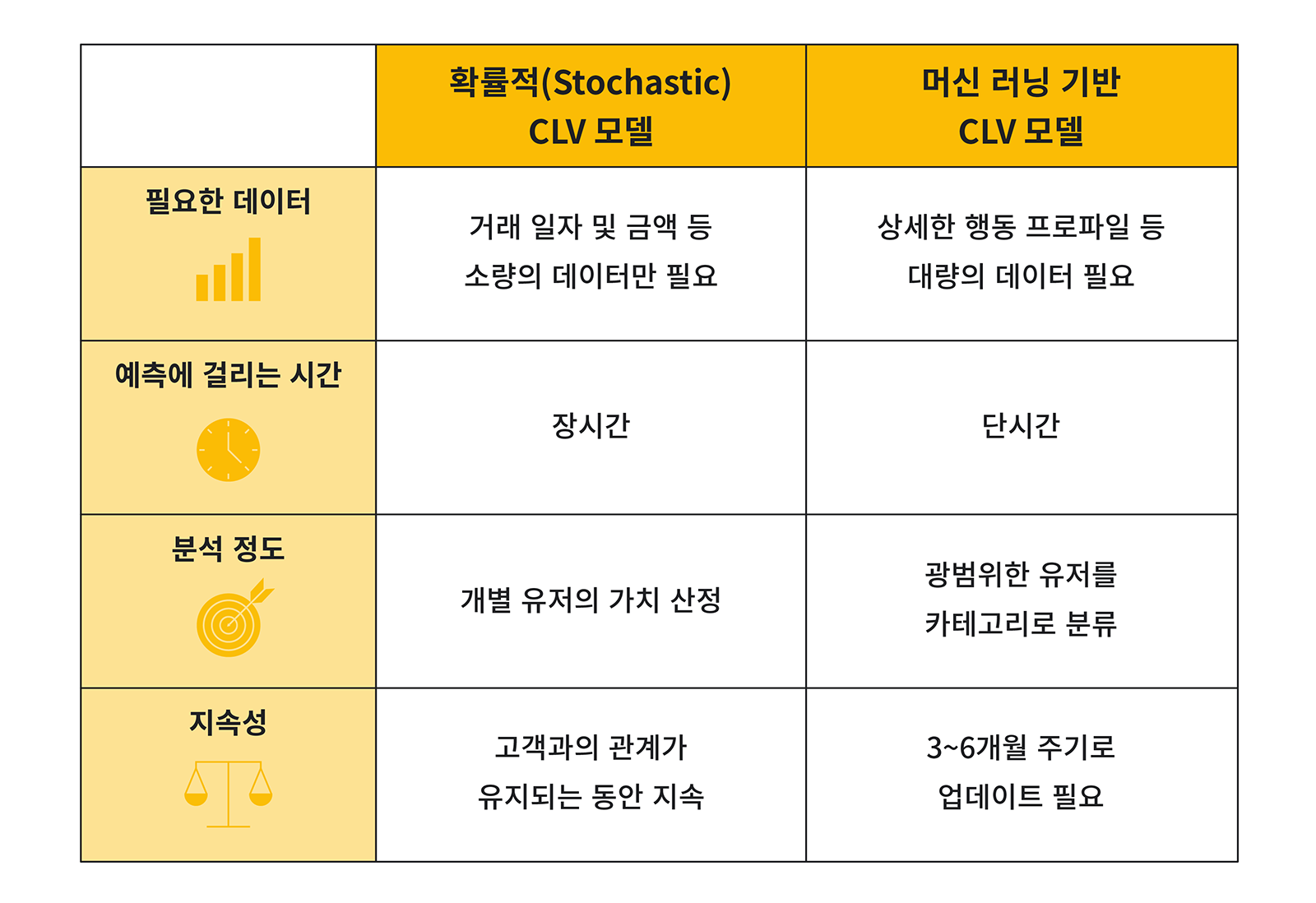
음이항 분포 모델(Negative binomial distribution)과 같은 여러 통계 모델이 정밀도와 장기적인 안정성 때문에 선호되고 있지만, 이러한 모델을 활용하려면 여러 기간에 걸쳐 고객을 관찰해야만 합니다. 따라서 이 방법은 며칠마다 성공 지표를 확인해야 하는 플랫폼에는 적합하지 않으며, 디지털 광고에 대한 입찰 최적화가 어려울 수 있습니다.
데이터를 효과적으로 활용하고 있는 광고주들은 정밀도는 떨어질 수 있지만 더 즉각적인 예측을 하기 위해 머신러닝을 사용하고, 고객과 관계가 형성되면 기존에 활용하던 기법들을 다시 사용하고 있습니다. 하지만 한 가지 방법만으로 모든 상황을 예측할 수 있다는 접근 방식을 버리고, 머신러닝과 무작위 변수 모델인 기존의 확률 모델을 번갈아 가며 사용할 필요가 있습니다.
대표적인 CLV 모델의 비교
4. 계속해서 새로운 고객을 찾으세요
CLV 모델의 주요 데이터 소스는 기업의 데이터이지만, 과거에 확보하고자 했던 고객 유형을 반영하고 있기 때문에 데이터가 편향될 수 있습니다. 예를 들어 기존의 마케팅 활동이 즉각적인 구매자를 대상으로 이루어졌다면, 확보한 데이터에는 브랜드와 장기적인 관계를 구축할 가능성이 있는 사람들이 적을 수 있습니다. 따라서 장기적인 성장의 원천이 될 수 있는 새로운 고객을 계속해서 찾고 유인하기 위한 마케팅 예산을 항상 따로 편성해 두는 것이 좋습니다. 다시 말해, 지금보다 더 가치 있는 고객을 찾기 위한 노력을 계속 기울여야 합니다.
장기적인 성장을 위해 새로운 고객을 찾고 이들을 유인할 수 있도록 마케팅 예산의 일부를 따로 편성해 두세요.
5. 다른 이해관계자들에게 CLV의 필요성을 인식시키세요
CLV를 도입하는 과정에서는 예산을 이동해야 하고, 도입했을 때의 성과에 대한 이해도 또한 떨어지며, 기존의 단기적인 투자에 대해 비판적으로 점검해야 하므로 마찰이 생길 수 있습니다. 처음부터 획기적인 변화를 시도할 필요는 없습니다. 대신 CLV를 수용할 수 있도록 관계자들에게 충분히 알리는 데 집중하세요. 다른 사람들이 CLV의 개념과 이것이 비즈니스에 어떻게 적용될 수 있는지 이해할 수 있도록 도와야 합니다. 실험을 통해 어떤 이점이 있을지 투명하게 알리고, 부서의 업무 프로세스에 어떤 영향을 미치는지에 대해 열린 의견을 나누세요. 이러한 신중한 접근방식은 더딜 수 있지만, 결과적으로 CLV를 도입하는 데 도움이 될 것 입니다.
결국 가장 중요한 것은 CLV를 적용하기 위해 비즈니스를 변화시키는 것이 아니라, CLV를 현재의 비즈니스에 통합할 방법을 찾는 것입니다. CLV 도입을 위한 가이드라인 및 권장사항을 염두에 두되, 지금까지 여러분의 비즈니스에서 개발한 모든 최적화 기법 및 프로세스를 훼손하지 않도록 주의하세요. 미래의 성공적인 마케팅을 위해서는 지금까지 성공을 거둘 수 있게 한 기존 방법들과 CLV를 병행하여 두 가지를 동시에 개선할 수 있는 방법을 찾아야 합니다.








