広告投資に対する収益率(ROI)を正確に測るには、広告のインプレッションやその効果をコンバージョンと適切に関連付けることが大切です。 しかし、利用者のプライバシー意識の高まりなどに伴い、利用できるデータが減少しているため、マーケターの求めるコンバージョンまでの経路を解明することが以前より難しくなってきています。
またデジタル広告業界では、ウェブ上の Cookie やアプリのデバイス ID など、個人を識別する仕組みから脱却しようという動きも進んでいます。広告効果を解析する際に、そうした単一のデータソースに頼ることができなくなってきているのです。
Google は、こうしたエコシステムの変化に対応できるよう取り組みを続けています。複雑なデータセットを、プライバシーを重視したモデリングソリューションを使って自動で分析し、コンバージョンに至るプロセスにおける未知の部分を解決しようとしています。
今回は US 版 Think with Google が公開した記事を基に、日本の読者向けに再編集しました。
効果測定のギャップを埋める「コンバージョン モデリング」
コンバージョン モデリングとは、プライバシーに配慮するためのさまざまな理由によって、コンバージョンの一部が広告インタラクションに直接結びつかない場合に、機械学習を使ってマーケティング活動の影響を評価することです。これにより、広告のパフォーマンスをより包括的かつ正確に把握できるようになります。
例として、iOS 上の広告について考えてみましょう。2021 年の App Tracking Transparency(ATT)の導入により、iOS では Cookie や IDFA(Identifier for Advertisers)のマーケティングへの活用がこれまでよりも限定的になっています。
利用者が iOS 上で Cookie や IDFA の広告への利用を認めなかった場合、その利用者が広告接触後に何らかのアクションを起こしたとしても、広告がビジネスにもたらした価値を明確には証明できなくなります。
また、あるユーザーグループのコンバージョン情報を集約しても、具体的にどの広告インタラクションがコンバージョンにつながったのかが正確にわからない場合もあります。
Google はこれらのようなケースを考慮し、コンバージョンを特定の広告インタラクションに結びつけられた場合は「検出可能」、結びつけられない場合は「検出不可能」に分類します。
検出不可能なユーザーグループについては、似た行動や特徴を持つ検出可能な別のグループの OS、デバイスの種類、時間帯などの情報から特定します。例えば、検出可能なグループによる広告インタラクションから、5% が購入に至った場合、このデータを用いてキャンペーンモデルを学習させることで、検出可能かどうかに関わらず、広告に対してアクションを起こしたすべてのユーザーによるコンバージョンの量を推定します。
検出可能かつプライバシーに配慮したシグナルに基づいたコンバージョンモデリングの基盤づくり
コンバージョンモデリングの正確性と信頼性を高めるには、検出可能なデータの基盤を築くことが不可欠です。このため Google では、以下の 3 つのデータソースを用いてコンバージョンモデリングを行っています。
1:ファーストパーティデータ
ファーストパーティデータには、IDFA やファーストパーティー Cookie、多数のデータを集約して匿名化したデータなどがあります。IDFA とファーストパーティー Cookie によって、利用者は、アプリやサイトパブリッシャーを通じて、広告のトラッキングやパーソナライゼーションを許可(オプトイン)しています。
2:プラットフォーム API からのデータ
プラットフォーム API からのデータには、SKAdNetwork や Google Chrome の プライバシー サンドボックス Attribution Reporting API などがあります。iOS アプリキャンペーンでは、クロスネットワーク測定フレームワークである SKAdNetwork を通じてアプリキャンペーンに紐付いているインストール数とコンバージョン数を計上しています。Web キャンペーンでは、クリックスルーやビュースルーのコンバージョンを利用者のプライバシーが保護された方法で測定できるようにAttribution Reporting API の開発を進めています。
3:類似のデータセット
類似のデータセットとは、広告に接した利用者と似た利用者の行動やコンバージョンパターンを集約したものです。これらのデータはモデルに反映され、特定のユーザー属性が、Google のアプリやウェブキャンペーンで提供される広告に接触した後、どのくらいの頻度でコンバージョンに至るかを計算することができます。同じ属性を持つユーザー数を調べ、その広告対コンバージョン比を適用してキャンペーンの総コンバージョン数を推定します。
プライバシーに配慮し、かつ、正確なコンバージョンモデリングを
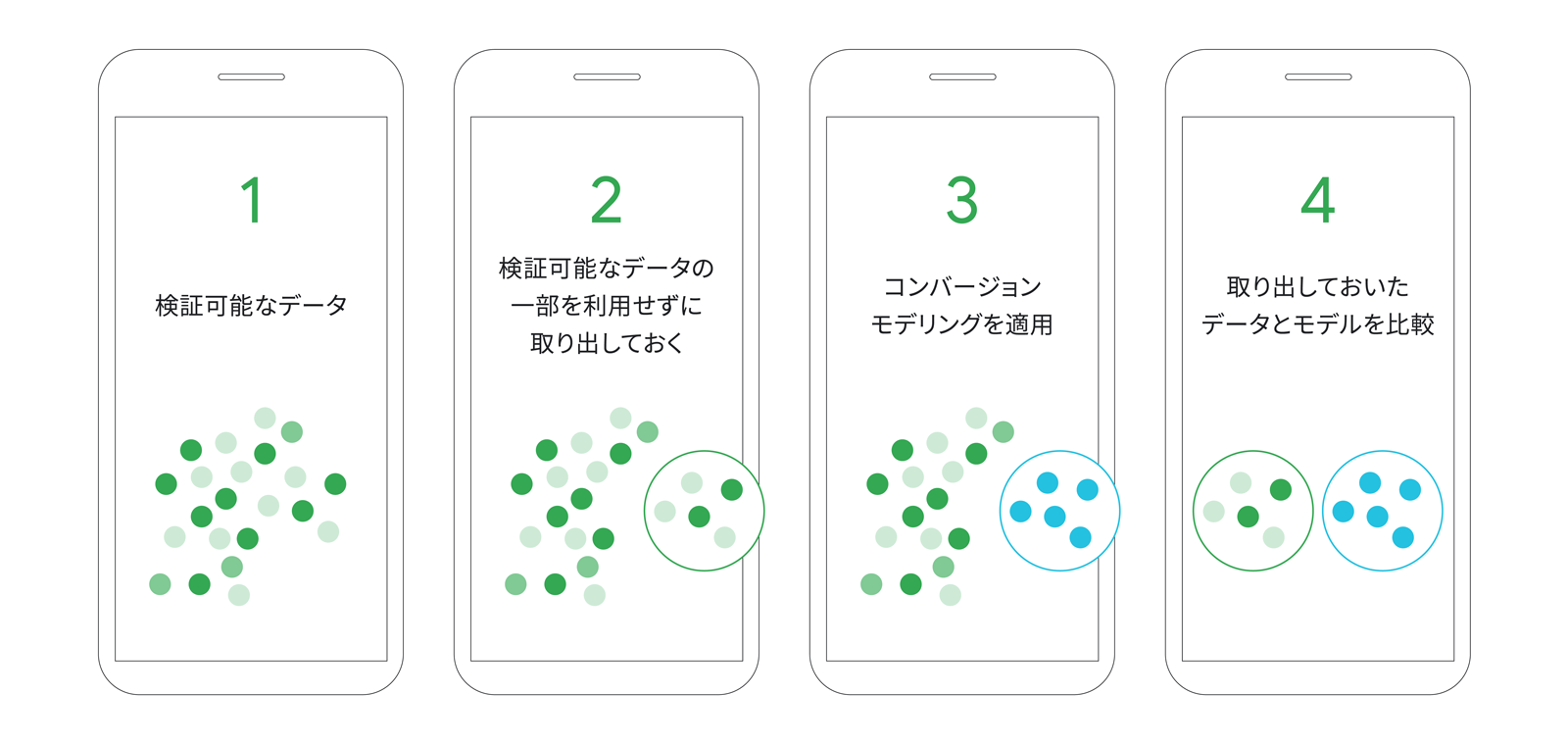
Google は、広告インタラクションの結果としてコンバージョンが発生したと確信できる場合にのみ、モデルから推定したコンバージョンを報告します。モデルの精度を検証するために、検証時のみ一部のデータをあえて利用せず、その代わりにコンバージョン モデルを適用します。このモデルから推計したコンバージョンと、実データのコンバージョンを比較して、大きな乖離がないことを確認し、各キャンペーンチャネルで発生したコンバージョン数を正しく計算または定量化できるようにしています。
このモデルは、機械学習における Google の専門知識を活用し、固有のユーザー行動やビジネスの成果に対応できるようになっています。例えば、多くの顧客が複数のデバイスから接触し、コンバージョンしている場合、Google のアルゴリズムは平均よりも高いクロスデバイスコンバージョンを報告します。キャンペーンのレポートにモデリングを統合することで、観測したコンバージョンデータとモデルから推計したコンバージョンデータを組み合わせて標準化したセットに、シームレスにアクセスでき、広告主の皆さんは分析と最適化の管理が容易になります。
当然ながらこの Google のモデルは、ユーザーのプライバシーを守りデータを保護することが最優先事項となっています。よって、複数のデータを集約して使うよう設計されており、フィンガープリントや IP アドレスなどから個々のユーザーを特定、追跡するようなプライバシーを侵害する手法を除外するよう、厳格なポリシーを定めています。
複雑なデータソースに対応した、これからの測定
Google のコンバージョン モデルはもともと、コンバージョンの一部(ウェブからアプリへのコンバージョン変換を含む)が完全に記録されていない場合に、複数のデータソースからの測定結果を補完するために開発されました。その結果、コンバージョン パスのギャップを埋め、より完全なパズルのように組み合わせることができるようになったのです。
デジタル広告業界では、利用者のプライバシー保護に伴う効果測定方法の変更が進んでいます。この変化にも積極的に対応し、広告主と媒体社の皆さまに負担をかけることなく、キャンペーンのパフォーマンスを継続的に計測し続けることができるよう取り組んでいます。