Déterminer l'impact de la publicité devrait être simple. "Le comportement de mes clients est-il différent lorsque je leur présente mes annonces ?". Une technologie permet de répondre plus facilement à cette question en identifiant les utilisateurs qui auraient été exposés. Ils correspondent au groupe témoin d'un test aléatoire mené sur les utilisateurs exposés. Quels sont les avantages de cette technologie par rapport aux autres méthodes de test ? Quelle est son importance dans le domaine de la modélisation d'attribution ?
Les difficultés rencontrées pour mener avec précision des tests d'annonces en ligne peuvent être nombreuses.
Mesurer l'efficacité des annonces : comment relever le défi ?
De nombreux annonceurs pensent que l'évaluation de l'impact publicitaire est une tâche facile, au même titre que la comparaison des résultats d'une campagne à l'autre. Malheureusement, les comparaisons effectuées à l'aide de modèles d'attribution simples, ou même plus complexes, ne considèrent pas toujours les annonces à leur juste valeur : certaines corrélations ne sont pas causales. Les tests impliquant des groupes expérimentaux et de contrôle représentent la norme scientifique la plus rigoureuse pour identifier les formules qui fonctionnent, et doivent être intégrées en tant qu'éléments importants de la stratégie d'attribution d'un annonceur. Quel est le test publicitaire idéal ?
Composants nécessaires pour mener des tests d'annonces précis
Dans le domaine de la publicité, un test scientifique comprend deux principales caractéristiques : un groupe cible bien défini et un contrôle précis de ceux qui sont autorisés à voir les annonces. Une campagne d'annonces ne touche jamais l'intégralité de l'audience cible, car l'annonce diffusée auprès d'un utilisateur dépend du comportement de celui-ci, des enchères proposées par les différents annonceurs en compétition et de nombreux paramètres de ciblage. Par conséquent, les utilisateurs touchés peuvent être complètement différents de ceux qui n'ont pas été exposés. Pour mesurer l'efficacité de la publicité, nous souhaitons procéder à une simple comparaison. "Le comportement des utilisateurs est-il différent lorsque je leur présente mes annonces ?" Pour ce faire, les utilisateurs cibles sont divisés aléatoirement en deux groupes : les annonces sont diffusées auprès du premier, mais pas du deuxième. En termes scientifiques, on se retrouve avec un groupe expérimental constitué d'utilisateurs réellement exposés et un groupe de contrôle constitué d'utilisateurs normalement exposés (mais avons choisi de ne pas le faire). C'est un moyen de comparer facilement les utilisateurs exposés aux utilisateurs potentiellement exposés.
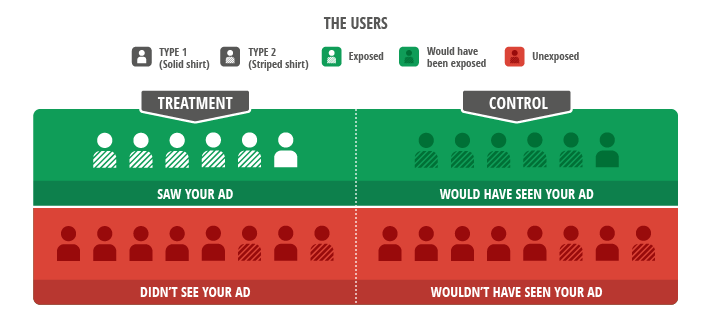
Figure 1 : Le test idéal compare les utilisateurs exposés aux utilisateurs potentiellement exposés. Les différences de comportement d'achat sont ici illustrées par les utilisateurs de type 1 (haut uni) et de type 2 (haut à rayures). Les groupes comparés doivent inclure le même mélange d'utilisateurs, afin de comparer ce qui est comparable. Pour réaliser un test publicitaire scientifique, il convient de définir un ensemble d'utilisateurs cibles, et de répartir les utilisateurs touchés (zone en vert) en deux groupes (expérimental et de contrôle) équilibrés. Il s'agit ensuite de comparer les actions effectuées par le groupe expérimental (en blanc) à celles effectuées par le groupe de contrôle (en gris). Comment identifier alors les utilisateurs qui ont vu les annonces ?
Approche 1 : Campagnes d'annonces d'intérêt public/d'espaces réservés
Il est facile de penser "je connais le test placebo, c'est facile". Il suffit de séparer en deux la liste de ciblage et de définir une seconde campagne comprenant une annonce d'espace réservé sans lien avec l'annonceur (par exemple, une annonce pour une association caritative ou d'intérêt public). Cette approche peut fonctionner en choisissant le coût pour mille impressions (CPM) et un serveur publicitaire très simple, mais vous devrez vous acquitter du coût média induit pour l'annonceur ou l'éditeur. Toutefois, les serveurs publicitaires modernes qui utilisent le coût par clic (CPC) et par action (CPA) ainsi que l'optimisation des créations faussent les tests basés sur les annonces d'intérêt public. Par exemple, si le réseau publicitaire choisit de diffuser les annonces qui génèrent souvent des revenus plus élevés, les différences de taux de clics (CTR) entre les annonces de l'annonceur et les annonces d'espace réservé auront pour conséquence l'affichage plus fréquent des créations associées à un CTR plus élevé. En outre, le réseau publicitaire diffusera les annonces auprès des types d'utilisateurs plus susceptibles d'effectuer un clic. Étant donné que les utilisateurs qui ont décidé de cliquer sur une annonce pour des accessoires ou des vêtements de sport sont probablement différents de ceux qui ont cliqué sur une annonce pour une association caritative, votre test reviendra à comparer l'incomparable. Effectué de cette manière, le test basé sur les annonces d'intérêt public génèrera donc soit des résultats trop optimistes, soit des faux négatifs.
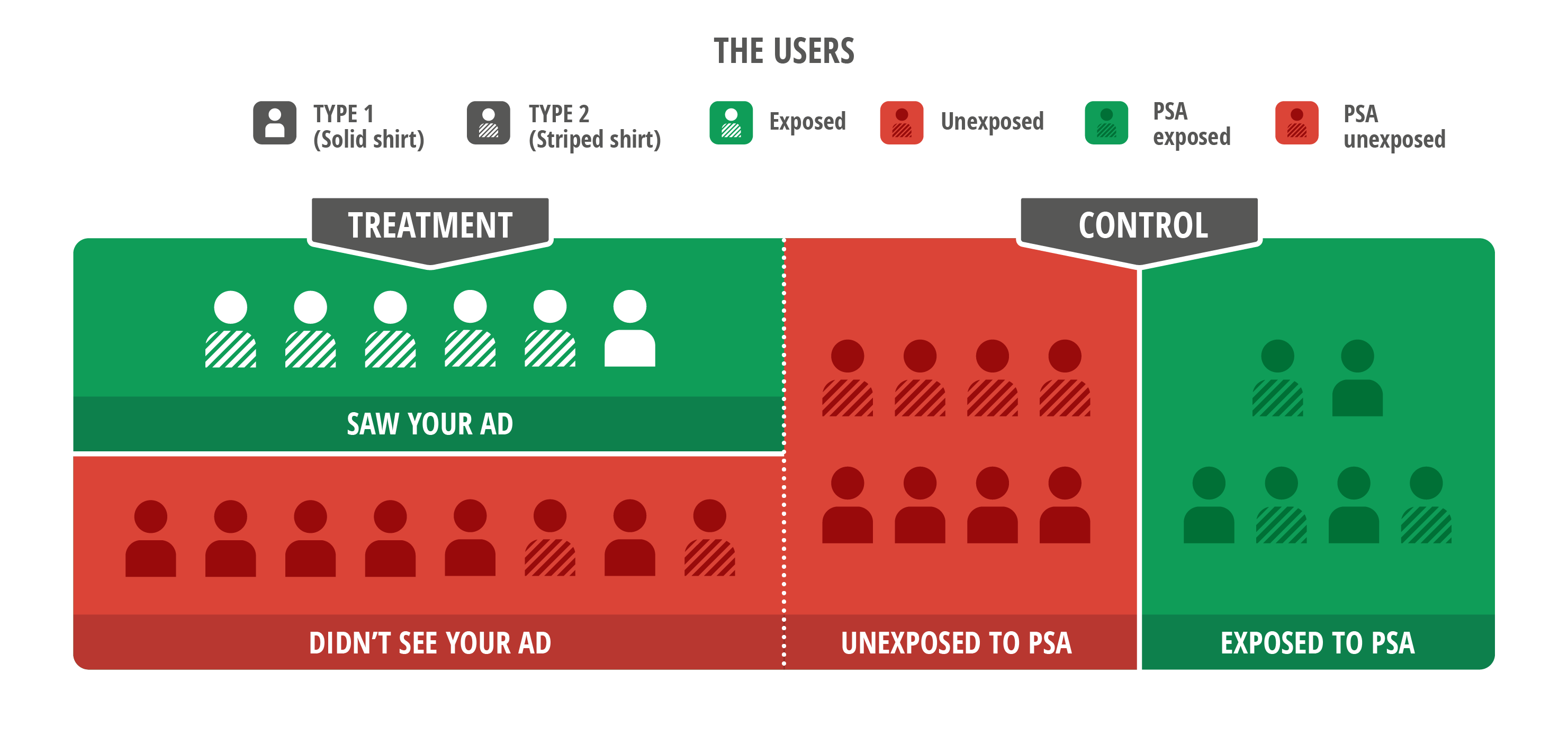
Figure 2 : Les tests basés sur les annonces d'intérêt public échouent avec les systèmes publicitaires modernes. Les réseaux publicitaires ne traitent pas les créations d'annonceur et d'intérêt public de la même manière. Ici, les optimisations effectuées par le serveur publicitaire provoquent la diffusion de l'annonce d'intérêt public auprès d'un groupe différent. Les deux groupes (utilisateurs exposés et non exposés) ne sont donc plus équilibrés. Une analyse effectuée dans le but de comparer les utilisateurs des zones en vert (groupes expérimentaux et de contrôle) ne serait pas valide : notez que les six utilisateurs exposés du groupe expérimental incluent cinq hauts rayés, tandis que le groupe de contrôle n'en comprend que trois. Les variations mesurées au niveau du comportement de conversion peuvent alors être davantage imputables aux différents types d'utilisateurs qu'aux effets de la publicité en elle-même.
Approche 2 : Intention de traiter
Cette méthode, qui consiste à ignorer toutes les informations liées à l'exposition des groupes expérimentaux et de contrôle, est un autre moyen d'analyser les résultats de tests effectués sans campagne d'annonces d'espace réservé. Par exemple, si nous divisons aléatoirement notre audience cible en deux listes et diffusons nos annonces auprès de l'une d'entre elles, nous pouvons comparer le comportement de l'ensemble des utilisateurs (pas seulement ceux qui ont vu l'annonce) appartenant à ces deux listes afin de mesurer l'effet de causalité de la publicité. En comparant tous les utilisateurs, quelle que soit la probabilité qu'ils aient vu les annonces, nous confrontons encore ceux qui ont été exposés à ceux qui auraient été exposés, mais nous intégrons en plus les données de ceux qui n'ont pas été exposés ou n'auraient pas été exposés. Cette méthode dite "en intention de traiter" est scientifiquement rigoureuse. On compare ce qui est comparable. Toutefois, les données superflues provenant des utilisateurs non touchés ne font pas réellement partie du test et sont souvent assez volumineuses. Une meilleure solution est donc attendue.
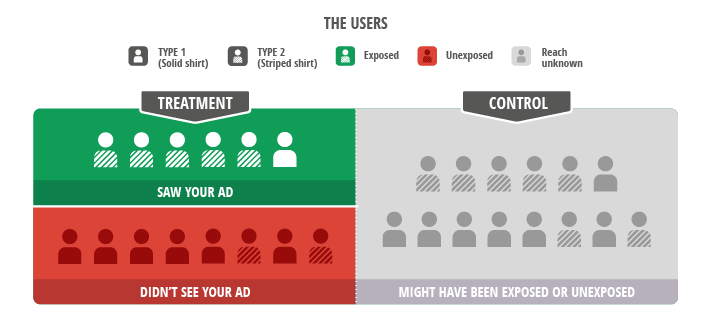
Figure 3 : Le test en intention de traiter ignore les informations relatives à l'exposition. Cette comparaison scientifiquement rigoureuse inclut tous les utilisateurs des groupes expérimentaux et de contrôle. Cette approche équilibrée intègre les données supplémentaires émanant des utilisateurs non touchés situés dans la zone en rouge (ceux que nous avions l'intention de toucher) et dans le groupe de contrôle. Les utilisateurs du groupe de contrôle qui auraient été exposés sont situés quelque part dans la zone en gris, mais nous ne savons pas où. Pourtant, si nous comparons l'ensemble du groupe expérimental (zones vertes et rouges) et le groupe de contrôle (zone grise), le mélange d'utilisateurs demeure inchangé, ce qui nous permet de procéder à une comparaison équitable.
Annonces de test : une solution idéale
La solution idéale combine les avantages des deux solutions présentées précédemment : une comparaison équitable intégrant les utilisateurs effectivement touchés par la campagne de l'annonceur. Cette technologie est appelée "annonces de test". Elles consignent les informations au moment où nous avons voulu diffuser l'annonce, ce qui nous assure que les utilisateurs du groupe de contrôle qui auraient été exposés sont comparables à ceux du groupe expérimental réellement exposés. Comme il n'utilise pas deux créations distinctes, comme avec la méthode de test basée sur les annonces d'intérêt public, le serveur publicitaire traite de la même manière les utilisateurs des deux groupes (avec une tarification au CPC ou au CPA), ce qui évite les irrégularités pouvant fausser les résultats. Enfin, puisque cette approche basée sur les annonces de test permet d'écarter les utilisateurs qui n'avaient aucune chance de voir l'annonce, on peut mesurer clairement les effets d'amélioration avec un niveau de précision jusqu'à 50 fois supérieur à la méthode en intention de traiter.
Les annonces de test présentent d'autres avantages. Premièrement, ni l'annonceur, ni le réseau publicitaire, ni l'éditeur ne génèrent de frais (contrairement à la diffusion des annonces d'intérêt public). Deuxièmement, avec un groupe de contrôle qui n'induit aucun coût, il est possible d'élaborer des tests plus complexes et plus instructifs. Troisièmement, au lieu de comparer les annonces de l'annonceur à des annonces artificielles non pertinentes, ce test repose sur une concurrence équitablement pertinente : les utilisateurs qui auraient été exposés voient toutes les annonces affichées naturellement lorsque l'annonceur désactive les annonces. Dernièrement, les annonces de test qui consignent les utilisateurs qui voient les annonces (par exemple, en se basant sur la visibilité) nous permettent de supprimer les données parasites émanant des internautes qui n'ont pas vu une annonce diffusée sur leur navigateur.
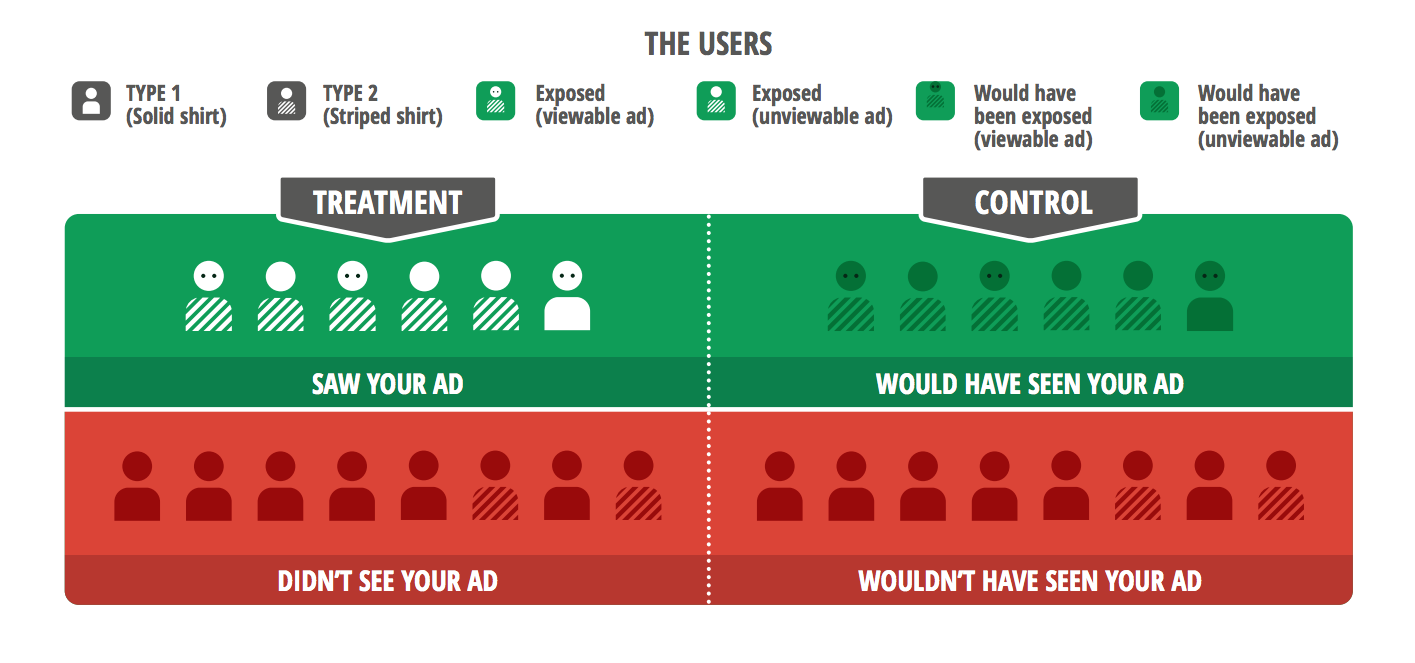
Figure 4 : L'efficacité des annonces de test peut être encore améliorée grâce aux informations sur la visibilité des annonces. Les annonces de ce type nous permettent de consigner les utilisateurs qui auraient été touchés ainsi que les autres données relatives à l'exposition, par exemple, la visibilité des annonces de test. Nous pouvons ainsi optimiser notre mesure. La meilleure comparaison d'efficacité des annonces s'intéresserait aux utilisateurs de la zone en vert pour lesquels les annonces étaient visibles (représentées par des yeux).
Perspectives d'avenir
Le chemin de la perfection est semé d'embuches. Comme pour les annonces d'intérêt public, de nombreux pièges doivent être évités. Les nouvelles technologies, telles que la visibilité des annonces, les enchères en temps réel, le reciblage/remarketing et la personnalisation des utilisateurs, ajoutent une couche de complexité pour les ingénieurs et nécessitent un processus de validation rigoureux. Google est connu pour investir dans les nouvelles technologies, parmi lesquelles figurent les annonces de test. Une étude de cas sur DefShop, un détaillant européen en ligne spécialisé dans le prêt-à-porter, présente cette nouvelle solution de mesure publicitaire.
Les annonces de test aident à valider et à améliorer les modèles d'attribution existants et créent une révolution dans le domaine de la mesure de l'efficacité publicitaire. Il est à espérer que le secteur intégrera ces annonces de test en tant que technologie clé permettant d'évaluer et d'optimiser les dépenses publicitaires.